...
This page describes the principles of creating core vocabularies and application profilesprofiles on the FI-Platform. It is important to understand these principles so that any ambiguities are avoided, as the modeling languages and paradigm used here differ from the traditional conceptual model used by many data architects and modeling tools (UML in particular). The end-goal of mastering the principles is that the formal content of your models are semantically equivalent to their visual and human-readable content, i.e. that your models speak of the same things both in machine and human readable formats. This is particularly important, as the primary aim of this modeling platform is to create and maintain semantic interoperability between actors - data and models should retain their meaning when they are shared or exchanged between parties.
...
When you mint a new HTTP URI for something, you can give it any name that adheres to RFC 3986, but as parts of the HTTP namespace are controlled (owned) by different parties, it is not a good principle to name things in namespaces owned by someone else unless specifically given permission. As an example, this modeling platform the FI-Platform gives every resource a name in the form of of <https://iri.suomi.fi/model/modelName/versionNumber/localName>, keeping all resources neatly inside the model's own versioned namespace (the https://iri.suomi.fi/model/modelName/versionNumber/ part). On the other hand, naming resources <https://suomi.fi/localName> would not be a good idea, as resolving these addresses is controlled by the DVV web server, resulting in either unresolved (HTTP 404) or clashes with other content already being served by the same URL.
As you are aware, there are some strict limitations with URIs - such as adhering to only ASCII characters. On the FI-Platform we have chosen to use IRIs instead. IRI is an Unicode extension of URI, meaning that both the domain and path parts of the identifier can contain a reasonable wide subset of characters from Unicode, which gives tremendous flexibility for supporting the needs of different modeling domains.
If you are managing data that you intend to distribute/share/transfer to other parties, it is good to adhere to the rule that all resources are given HTTP URI names from a namespace (domain If you are managing data that you intend to distribute/share/transfer to other parties, it is good to adhere to the rule that all resources are given HTTP URI names from a namespace (domain or IP address) that a) you control and b) are resolved to something meaningful.
...
As you can see, the model consists of only atomic parts with nothing inside them. We can say that conceptually it is the resource <https://finland.fi/> that contains the number of lakes or its type, but on the level of data structures, there is no containment. This is in stark contrast to typical data modeling paradigms, where entities are specified as templates or containers with mandatory or optional components. As an example, UML classes are static in the sense that they cannot be expanded to cover facets that were not part of the original design. On the other hand, we can expand the resource <https://finland.fi/> to have an unlimited amount of facts, even conflicting ones if our intention is to compare or harmonize data between datasets. We could for example have two differing values for the number of lakes with additional information on the counting method, time and responsible party in order to analyze the discrepancy.
Linked Data Can Refer
...
to Non-
...
Linked Data
You might have already guessed that this kind of graph data structure becomes cumbersome when it is used for example to store lists or arrays. Both are possible in RDF, but the flexibility of linked data allows us to leverage the fact that the same URI can offer us a large dataset e.g. in JSON format with the proper content accept type, while using the same URI as the identifier for the dataset and offer relevant RDF description of it. Additionally, e.g. REST endpoint URLs that point to individual records or fragments of a dataset can also be used to allow us to talk about individual dataset records in RDF while simultaneously keeping the original data structure and access methods intact. The URL based ecosystem does not have to be aware of the semantic layer that is added on top or parallel to it, so implementing linked data based semantics to your information management systems and flows is not by default disruptive.
...
A small exception to the naming rule is that the literal integer value of 187888 does not have an identity (nor do any other literal values). From the diagram it is evident that both individuals ("instances") and classes are named the same way and can coexist in the same graph. This is not a problem, as they are distinguished by their relationships (Additionally, in linked data it is possible to utilize the concept of punning which means that the same resource acts simultaneously as an individual and a class, but this is an advanced topic and not covered here).
All Resources Are First-Class CitizensAll Resources Are First-Class Citizens
In traditional UML modeling classes are the primary entities with other elements being subservient to them. In RDF this is not the case. Referring to the diagram above, e.g. the resource <https://datamodel/hashasCapital> is not bound to be only an association, even though here it is used as such. As it has been named with a URI, we can use it as the subject of additional triples that describe it. We could - for example - add triples that describe its meaning or metadata about its specification. So, when reading the diagrams you should always keep in mind that the sole reason some resources are represented as edges is due to the fact that they appear in the stated triples in the predicate position.
...
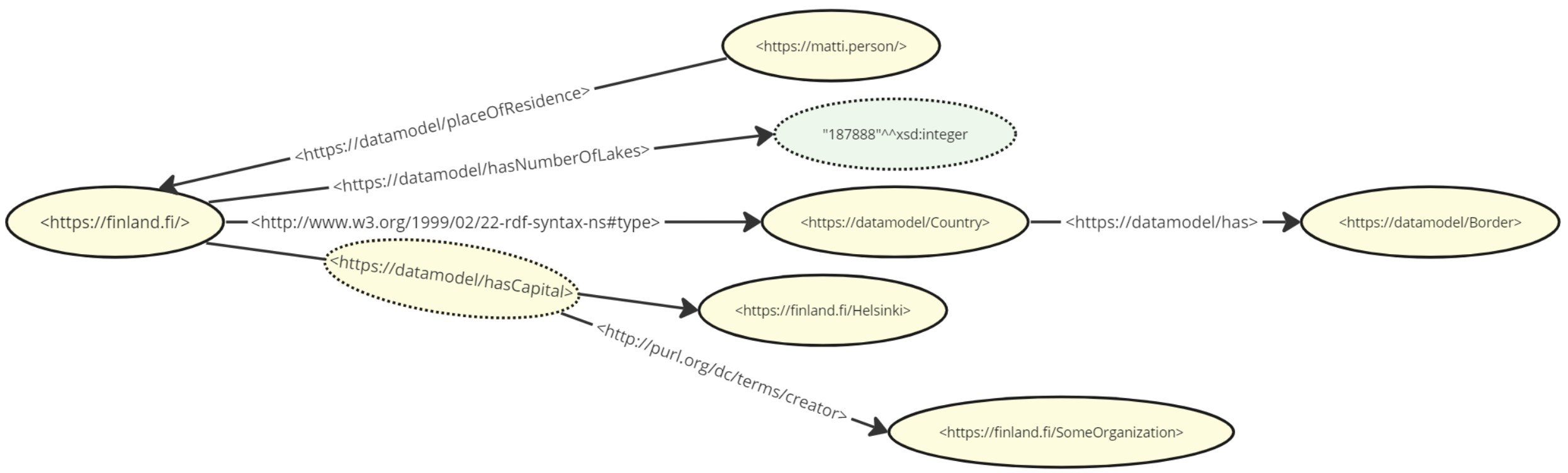
Above, you can see another triple where the creator of the <https://datamodel/hasCapital> resource is stated as being some organization under the <https://finland.fi/> namespace.
Data and Model Can Coexist
From the diagrams above it is evident that both individuals ("instances") and classes are named the same way and can coexist in the same graph. From the plain linked data perspective such a distinction doesn't even exist: there are just resources pointing to other resources with RDF. Where the distinction becomes important is when the data is interpreted through the lens of a knowledge description language where some of the resources have a special meaning for the processing software. The meaning of these resources become evident when we discuss the core vocabularies and application profiles.
Relationships Are Binary
Third key takeaway is that all relationships are binary. This means that these kind of structures (n-ary relationships) are not possible:
...
Stating this would always require two triples with each one using the same "has child" as its predicate, meaning the association is used twice. This means that treating them as one requires an additional grouping structure, for example in the case where all of the child associations would share some feature that we do not want to replicate for each individual association. Also, you might
Another
...
You're not Modelling records but the Entities
What all the resources in a linked data dataset are , depends of course entirely on the use case at hand. There In general though, there is a deep philosophical distinction though between how linked data and traditional data modelingapproach modelling. Traditionally data modeling modelling is done in a siloed way with an emphasis on modeling modelling records, in other words a data structure that describes a set of data for a specific use case. As an example, different information systems might hold data about an individual's income taxes, medical history etc. These data sets relate to the individual indirectly via some kind of a permanent identifier, such as the finnish Personal Identity Code, but the . The identifier nor the records are meant to represent the concepts records of income taxes, places of residence, medical history, etc. Through unique identifiers these records can be connected to the individual in question, but there is a clear separation of concerns: the data model the concepts themselves but just a the relevant data of them. The data is typically somewhat denormalized and serves a process or system view of the domain at hand.With
On the other hand, in linked data the records view of the world is certanily possible to model and in some cases the appropriate solution, but in principle, linked data due to being in graph format allows statements of the world to be expressed in a much more natural wayAs an examplemodelling of specific entities is often approached by assuming that the minted URIs (or IRIs) are actually names for the entities themselves.
Core Vocabularies (Ontologies)
...