...
This page describes the principles of creating core vocabularies and application profiles on the FI-Platform. It is important to understand these principles so that any ambiguities are avoided, as the modeling languages and paradigm used here differ from the traditional conceptual model used by many data architects and modeling tools (UML in particular). The end-goal of mastering the principles is that the formal content of your models are semantically equivalent to their visual and human-readable content, i.e. that your models speak of the same things both in machine and human readable formats. This is particularly important, as the primary aim of this modeling platform is to create and maintain semantic interoperability between actors - data and models should retain their meaning when they are shared or exchanged between parties.
In this guide we have highlighted the essential bits of knowledge with (note) symbols.
The Linked Data Modeling paradigm
...
As you can imagine based on the name, linked data is all about references (links or "pointers") between entities (pieces of data). In principle:
All entities (resources in the linked data jargon) in the data are named with URIs (Uniform Resource Identifier).
How to Name Things
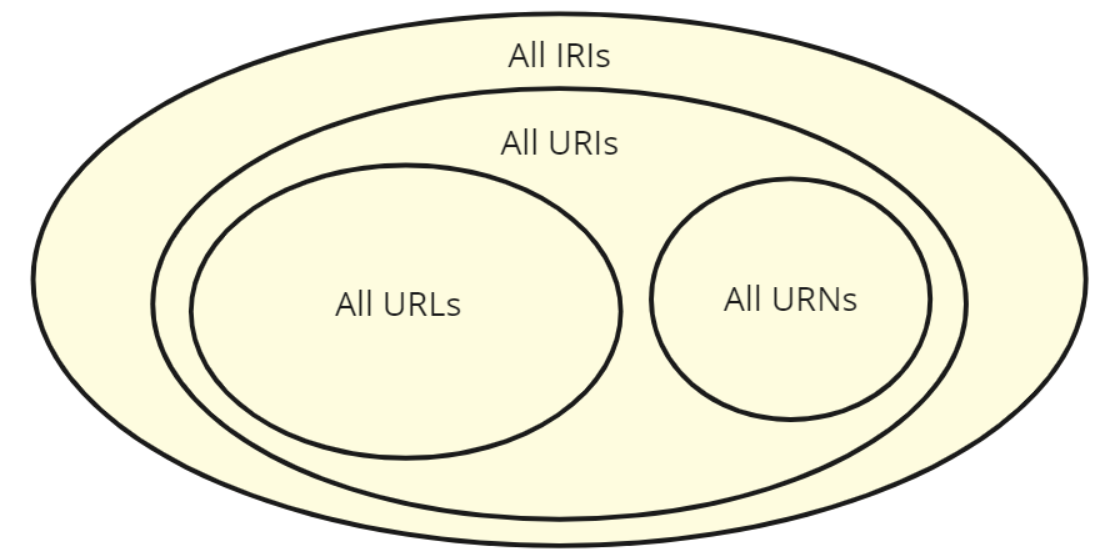
As mentioned, all resources are named ("minted") with URI identifiers, which we can then use to refer to them when needed. URLs and URNs are form subsets of URIs (which in turn is a subset of URIsall IRIs), so any URL - be it for an image, web site, REST endpoint address or whatever - is already ready to be incorporated to the linked data ecosystem. URNs (e.g. urn:isbn:0-123-456-789-123) can be used as well, but unlike the aforementioned URLs they can't be directly resolved. URNs with their own sub-namespaces have specific use cases (ISBN, EAN, DOI, UUID etc.) where they are preferred, but in general you should aim towards creating HTTP URIs (or to be more precise HTTP IRIs as explained later). The difference between an URL and HTTP URI/IRI is that the first is an address for locating something whereas the latter conceptually acts also as an identifier for naming it.
There is a deep philosophical difference and reasons between how and what things are named in linked data compared to traditional data modeling e.g. with UML, but covering this requires going through the some elementary principles first. We won't go deeply into the conceptual basis of URIs in this text, but the most important thing to keep in mind is: URLs only point to resources on the Web, whereas URIs are meant to describe any resources - also abstract or real-world ones. As an example, Finland as a country is not a resource created specifically and existing only on the Web, but it can still be named with a HTTP URI so that it can be described in machine-readable terms and used in information systems.
When you mint a new HTTP URI for something, you can give it any name that adheres to RFC 3986, but as parts of the HTTP namespace are controlled (owned) by different parties, it is not a good principle to name things in namespaces owned by someone else unless specifically given permission. As an example, the FI-Platform gives every resource a name in the form of <https://iri.suomi.fi/model/modelName/versionNumber/localName>, keeping all resources neatly inside the model's own versioned namespace (the https://iri.suomi.fi/model/modelName/versionNumber/ part). On the other hand, naming resources <https://suomi.fi/localName> would not be a good idea, as resolving these addresses is controlled by the DVV web server, resulting in either unresolved (HTTP 404) or clashes with other content already being served by the same URL. You can think of the localName part of the URI as identical to the local names of XML or UML elements. The namespace is a core part of XML and UML schemas as well, but in (HTTP URI based) linked data each element is referred to with a global identifier - thus making it unambiguous to know which element we are talking about even if two elements have the same local names.
How do we then identify what the local name part of the URI is? There are two methods, but both require that you follow the RFC:s correctly. There is a multitude of ways both users and Web services use malformed URIs, and browsers and web servers encourage this kind of behaviour by autocorrecting many malformed URIs before the request is sent or when it is received.
the format shown above is called a raw URI, but when looking at linked data serializations, you might stumble upon a familiar representation from XML: namespaceName:localName. This is called a CURIE (Compact URI Expression), where the namespace is given a shorter easier to read name and it is concatenated with the local name with a colon. This only aids the human-readability of the serializations, and requires that you always keep the context (namespace names to namespace URI mappings) with the data. Otherwise you will end up with unusable data if you combine CURIE form datasets that use colliding namespace names for different namespace URIs. This is not a problem when managing linked data with software, only when editing it manually.
As you are aware, there are some strict limitations with URIs - such as adhering to only ASCII characters. On the FI-Platform we have chosen to use IRIs instead. IRI is an Unicode extension of URI, meaning that both the domain and path parts of the identifier can contain a reasonable wide subset of characters from Unicode, which gives tremendous flexibility for supporting the needs of different modeling domains. There are some things to consider, namely that the domain part is handled differently from the path part of the URI. All internationalized domain names need to be punycoded (represented as ASCII) and don't support case-sensitivity, whereas the path part is case-sensitive and supports Unicode. Also, you should be aware that every IRI can be converted to URI for backwards-compatibility, which will naturally also create potential collisions, as there is no way to distinguish the ASCII version of an IRI from a URI. It is recommended to use only software that can deal with IRIs natively without requiring any conversion. Also, per the RFC, you must be aware that two identifiers are declared the same if and only if they match exactly character by character. This means for example that an IRI containing e.g. scandinavic letters and its URI-conversion are not the same identifier. We do have the capability to say that they are the same, but how to do it is explained later on in the textAs you are aware, there are some strict limitations with URIs - such as adhering to only ASCII characters. On the FI-Platform we have chosen to use IRIs instead. IRI is an Unicode extension of URI, meaning that both the domain and path parts of the identifier can contain a reasonable wide subset of characters from Unicode, which gives tremendous flexibility for supporting the needs of different modeling domains.
If you are managing data that you intend to distribute/share/transfer to other parties, it is good to adhere to the rule that all resources are given HTTP URI names from a namespace (domain or IP address) that a) you control and b) are resolved to something meaningful.
...
You might have already guessed that this kind of graph data structure becomes cumbersome when it is used for example to store lists or arrays. Both are possible in RDF, but the flexibility of linked data allows us to leverage the fact that the same URI can offer us a large dataset e.g. in JSON format with the proper content accept type, while using the same URI as the identifier for the dataset and offer relevant RDF description of it. Additionally, e.g. REST endpoint URLs that point to individual records or fragments of a dataset can also be used to allow us to talk about individual dataset records in RDF while simultaneously keeping the original data structure and access methods intact. The URL based ecosystem does not have to be aware of the semantic layer that is added on top or parallel to it, so implementing linked data based semantics to your information management systems and flows is not by default disruptive.
Let us take an example: you might have a REST API that serves photos as JPEGs with a path: https://archive.myserver/photos/localName.
Everything Has an Identity
...