This page describes the principles of creating core vocabularies and application profiles on the FI-Platform. It is important to understand these principles so that any ambiguities are avoided, as the modeling languages and paradigm used here differ from the traditional conceptual model used by many data architects and modeling tools (UML in particular). The end-goal of mastering the principles is that the formal content of your models are semantically equivalent to their visual and human-readable content, i.e. that your models speak of the same things both in machine and human readable formats. This is particularly important, as the primary aim of this modeling platform is to create and maintain semantic interoperability between actors - data and models should retain their meaning when they are shared or exchanged between parties.
In this guide we have highlighted the essential bits of knowledge with (note) symbols.
The Linked Data Modeling paradigm
The models published on this platform are part of the linked data ecosystem. Putting the models into use in your own domain or organization though does not require a major overhaul of your information systems nor migrating your data into linked data. There are multiple pathways to utilize the models, from lightweight integration to full-fledged solutions. We will go through these options later, but first we will go through the key features of linked data.
How we organize and connect data greatly impacts our ability to use it effectively. Linked data offers a structured approach to data management that extends beyond its traditional uses both within closed organizational environments as well as publicly on the Internet. Typically, information systems tend to be siloed, requiring tailor-made and often fragile ETL (Extract, Transform, Load) processes for data interoperability. These ETL solutions, while necessary, do not inherently carry machine-readable semantics, leaving the interpretation and contextual understanding of the data largely to human operators. In contrast, linked data enables embedding rich, machine-readable semantics within the data itself, facilitating automated processing and integration. Additionally - as inherent in its name - linked data makes connecting datasets from heterogeneous sources and referencing other data (down to individual entities) tremendously easy. These capabilities not only enhance data usability but also provide the basis for more interoperable, intelligent and dynamic replacements for traditional data catalog, warehousing and similar management solutions.
Linked data based knowledge representation, validation and query languages are frameworks used to create, structure, and link data so that both humans and machines can understand its meaning and use it efficiently. They are part of the broader ecosystem known as the Semantic Web, which aims to make data on the entire World Wide Web readable by machines as well as by humans.
Linked data models are instrumental in several ways:
- Data Integration: They facilitate the combination of data from diverse sources in a coherent manner. This can range from integrating data across different libraries to creating a unified view of information that spans multiple organizations.
Interoperability: A fundamental benefit of using linked data models is their ability to ensure interoperability among disparate systems. Data structured particularly with linked data knowledge representation languages such as OWL, SKOS or RDFS, can be shared, understood, and processed in a consistent way, regardless of the source. This capability is crucial for industries like healthcare, where data from various providers must be combined and made universally accessible and useful, or in supply chain management, where different stakeholders (manufacturers, suppliers, distributors) need to exchange information seamlessly.
Knowledge Management: These models help organizations manage complex information about products, services, and internal processes in a way that is easily accessible and modifiable. This structured approach supports more efficient retrieval and use of information.
Artificial Intelligence and Machine Learning: The knowedge representation languages provide a structured context for data, which is essential for training machine learning models. This structure allows AI systems to interpret data more accurately and apply learning to similar but previously unseen data. By using linked data models, organizations can ensure that their data is not only accessible and usable within their own systems but can also be easily linked to and from external systems. This creates a data ecosystem that supports richer, more connected, and more automatically processable information networks.
Enhancing Search Capabilities: By providing detailed metadata and defining relationships between data entities, these models significantly improve the precision and breadth of search engine results. This enriched search capability allows for more detailed queries and more relevant results.
When discussing linked data models, particularly in the context of the Semantic Web, there are two primary categories to consider: core vocabularies (ontologies) and application profiles (schemas). Each serves a unique role in structuring and validating data. We will explore these two categories after introducing linked data which functions as their foundation.
The Core Idea of Linked Data
As you can imagine based on the name, linked data is all about references (links or "pointers") between entities (pieces of data). In principle:
All entities (resources in the linked data jargon) in the data are named with URIs (Uniform Resource Identifier).
How to Name Things
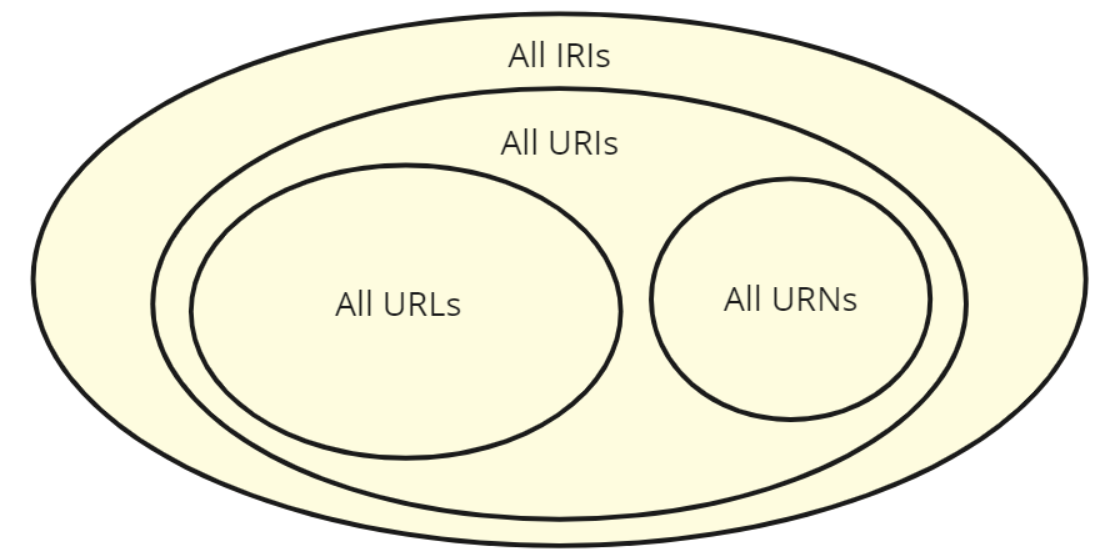
As mentioned, all resources are named ("minted") with URI identifiers, which we can then use to refer to them when needed. URLs and URNs form subsets of URIs (which in turn is a subset of all IRIs), so any URL - be it for an image, web site, REST endpoint address or whatever - is already ready to be incorporated to the linked data ecosystem. URNs (e.g. urn:isbn:0-123-456-789-123) can be used as well, but unlike the aforementioned URLs they can't be directly resolved. URNs with their own sub-namespaces have specific use cases (ISBN, EAN, DOI, UUID etc.) where they are preferred, but in general you should aim towards creating HTTP URIs (or to be more precise HTTP IRIs as explained later). The difference between an URL and HTTP URI/IRI is that the first is an address for locating something whereas the latter conceptually acts also as an identifier for naming it.
There is a deep philosophical difference and reasons between how and what things are named in linked data compared to traditional data modeling e.g. with UML, but covering this requires going through some elementary principles first. We won't go deeply into the conceptual basis of URIs in this text, but the most important thing to keep in mind is: URLs only point to resources on the Web, whereas URIs are meant to describe any resources - also abstract or real-world ones. As an example, Finland as a country is not a resource created specifically and existing only on the Web, but it can still be named with a HTTP URI so that it can be described in machine-readable terms and used in information systems.
When you mint a new HTTP URI for something, you can give it any name that adheres to RFC 3986, but as parts of the HTTP namespace are controlled (owned) by different parties, it is not a good principle to name things in namespaces owned by someone else unless specifically given permission. As an example, the FI-Platform gives every resource a name in the form of <https://iri.suomi.fi/model/modelName/versionNumber/localName>, keeping all resources neatly inside the model's own versioned namespace (the https://iri.suomi.fi/model/modelName/versionNumber/ part). On the other hand, naming resources <https://suomi.fi/localName> would not be a good idea, as resolving these addresses is controlled by the DVV web server, resulting in either unresolved (HTTP 404) or clashes with other content already being served by the same URL. You can think of the localName part of the URI as identical to the local names of XML or UML elements. The namespace is a core part of XML and UML schemas as well, but in (HTTP URI based) linked data each element is referred to with a global identifier - thus making it unambiguous to know which element we are talking about even if two elements have the same local names.
How do we then identify what the local name part of the URI is? There are two methods, but both require that you follow the RFC:s correctly. There is a multitude of ways both users and Web services use malformed URIs, and browsers and web servers encourage this kind of behaviour by autocorrecting many malformed URIs before the request is sent or when it is received.
the format shown above is called a raw URI, but when looking at linked data serializations, you might stumble upon a familiar representation from XML: namespaceName:localName. This is called a CURIE (Compact URI Expression), where the namespace is given a shorter easier to read name and it is concatenated with the local name with a colon. This only aids the human-readability of the serializations, and requires that you always keep the context (namespace names to namespace URI mappings) with the data. Otherwise you will end up with unusable data if you combine CURIE form datasets that use colliding namespace names for different namespace URIs. This is not a problem when managing linked data with software, only when editing it manually.
As you are aware, there are some strict limitations with URIs - such as adhering to only ASCII characters. On the FI-Platform we have chosen to use IRIs instead. IRI is an Unicode extension of URI, meaning that both the domain and path parts of the identifier can contain a reasonable wide subset of characters from Unicode, which gives tremendous flexibility for supporting the needs of different modeling domains. There are some things to consider, namely that the domain part is handled differently from the path part of the URI. All internationalized domain names need to be punycoded (represented as ASCII) and don't support case-sensitivity, whereas the path part is case-sensitive and supports Unicode. Also, you should be aware that every IRI can be converted to URI for backwards-compatibility, which will naturally also create potential collisions, as there is no way to distinguish the ASCII version of an IRI from a URI. It is recommended to use only software that can deal with IRIs natively without requiring any conversion. Also, per the RFC, you must be aware that two identifiers are declared the same if and only if they match exactly character by character. This means for example that an IRI containing e.g. scandinavic letters and its URI-conversion are not the same identifier. We do have the capability to say that they are the same, but how to do it is explained later on in the text.
If you are managing data that you intend to distribute/share/transfer to other parties, it is good to adhere to the rule that all resources are given HTTP URI names from a namespace (domain or IP address) that a) you control and b) are resolved to something meaningful.
There is an exception though: if all the information is a) managed in a siloed environment and b) can be represented explicitly as linked data requiring no resolving, you can freely use any URIs you wish without worrying about them resolving to anything nor conflicting with existing URIs outside your environment. This means that you can also mint URIs for resources before you have a framework ready for resolving them.
Linked Data is Atomic
It is crucial to understand that by nature, linked data is atomic and always in the form of a graph. The lingua franca of linked data is RDF (Resource Description Framework), which allows for a very intuitive and natural way of representing information. In RDF everything is expressed as triples (3-tuples): statements consisting of three components (resources). You can think of triples as simply rows of data in a three column data structure: the first column represents the subject resource (from whose point of view the statement is made), the second column represents the context resource of what is being stated by the subject, and the third column represents the object or value resource of the statement. Simplified to the extreme, "Finland is a country" is a statement in this form:

If all data is explicitly in RDF, it means we have a fully atomic dataset where everything from the types of entities down to their attributes exist as individual resources (nodes) connected by associations (edges). If we expand the example above to also include statements about the number of lakes and Finland's capital, we could end up with the following dataset:
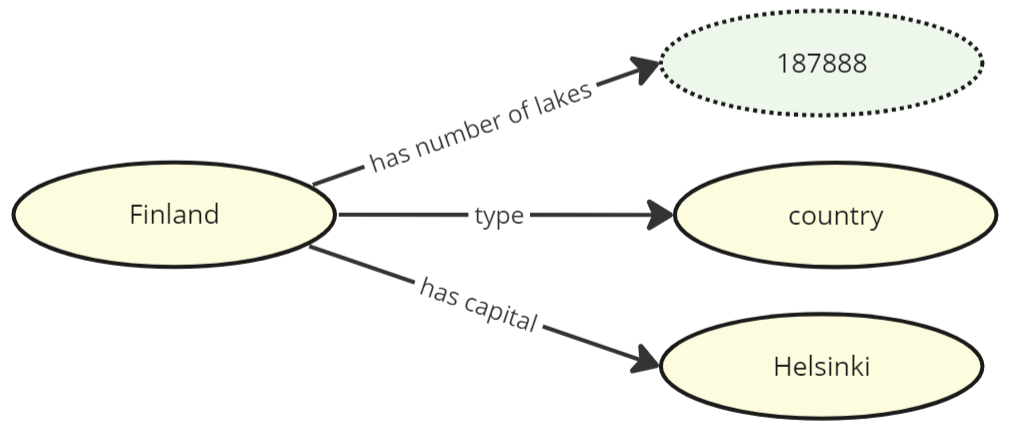
As you can see, there is no traditional class/instance structure with inner fields. Finland as an entity does not have fixed attribute slots inside it for the number of lakes nor its capital: everything is expressed by simply adding more associations between individual nodes. As mentioned above, everything is named with an URI, so a more realistic example would actually look like this:
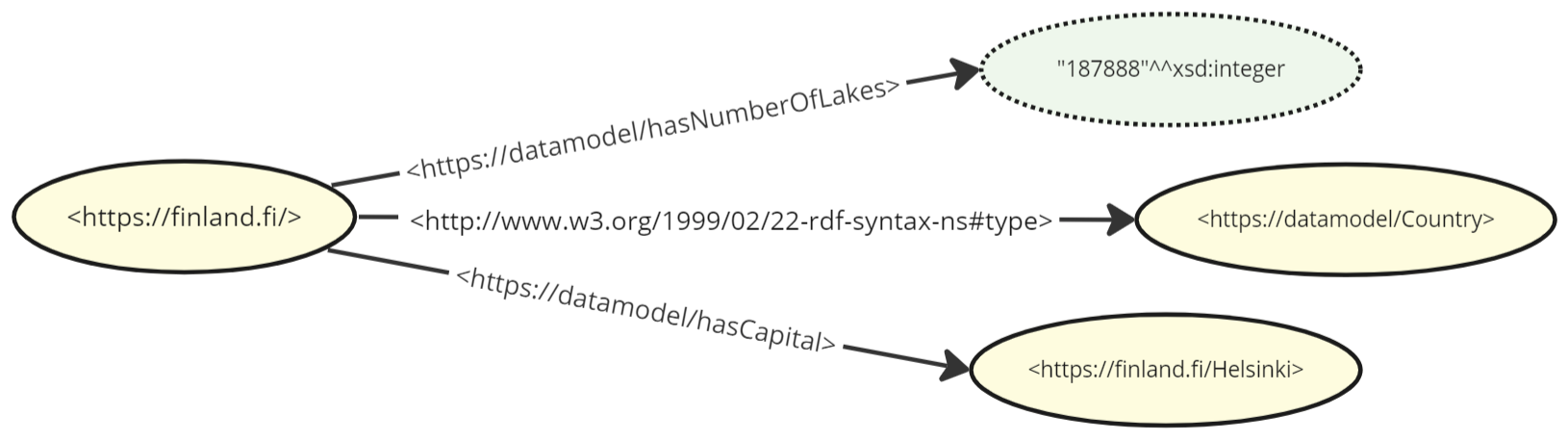
The triples in this dataset can be serialized very simply as three triples each consisting of three resources, or represented as a three column tabular structure:
| subject resource | predicate resource | object resource |
|---|---|---|
<https://finland.fi/> | <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> |
|
<https://finland.fi/> | <https://datamodel/hasNumberOfLakes> |
|
<https://finland.fi/> | <https://datamodel/hasCapital> |
|
As you can see, the model consists of only atomic parts with nothing inside them. We can say that conceptually it is the resource <https://finland.fi/> that contains the number of lakes or its type, but on the level of data structures, there is no containment. This is in stark contrast to typical data modeling paradigms, where entities are specified as templates or containers with mandatory or optional components. As an example, UML classes are static in the sense that they cannot be expanded to cover facets that were not part of the original design. On the other hand, we can expand the resource <https://finland.fi/> to have an unlimited amount of facts, even conflicting ones if our intention is to compare or harmonize data between datasets. We could for example have two differing values for the number of lakes with additional information on the counting method, time and responsible party in order to analyze the discrepancy.
Linked Data Can Refer to Non-Linked Data
You might have already guessed that this kind of graph data structure becomes cumbersome when it is used for example to store lists or arrays. Both are possible in RDF, but the flexibility of linked data allows us to leverage the fact that the same URI can offer us a large dataset e.g. in JSON format with the proper content accept type, while using the same URI as the identifier for the dataset and offer relevant RDF description of it. Additionally, e.g. REST endpoint URLs that point to individual records or fragments of a dataset can also be used to allow us to talk about individual dataset records in RDF while simultaneously keeping the original data structure and access methods intact. The URL based ecosystem does not have to be aware of the semantic layer that is added on top or parallel to it, so implementing linked data based semantics to your information management systems and flows is not by default disruptive.
Let us take an example: you might have a REST API that serves photos as JPEGs with a path: https://archive.myserver/photos/localName.
Everything Has an Identity
Because the above mentioned resources are all HTTP URIs (with the exception of the literal integer value for the number of lakes), we are free to refer to them to either expand the domain of this dataset or combine it with another dataset to cover new use cases. The killer feature of linked data is the ability to enrich data by combining it easily and infer new facts from it. As an example, we could expand the model to add the perspective of an individual ("Matti resides in Finland") and of a class ("A country has borders"):
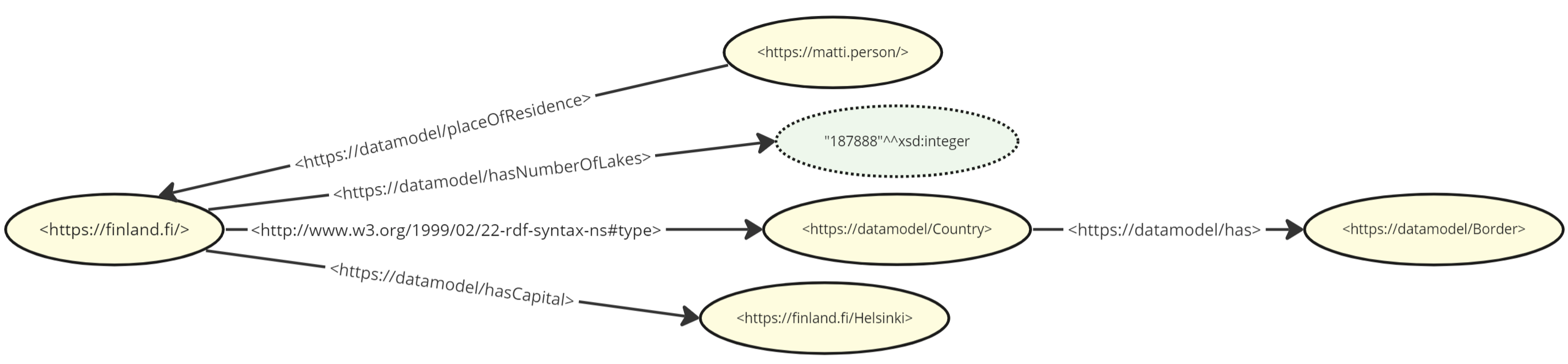
A small exception to the naming rule is that the literal integer value of 187888 does not have an identity (nor do any other literal values).
All Resources Are First-Class Citizens
In traditional UML modeling classes are the primary entities with other elements being subservient to them. In RDF this is not the case. Referring to the diagram above, e.g. the resource <https://datamodel/hasCapital> is not bound to be only an association, even though here it is used as such. As it has been named with a URI, we can use it as the subject of additional triples that describe it. We could - for example - add triples that describe its meaning or metadata about its specification. So, when reading the diagrams you should always keep in mind that the sole reason some resources are represented as edges is due to the fact that they appear in the stated triples in the predicate position.
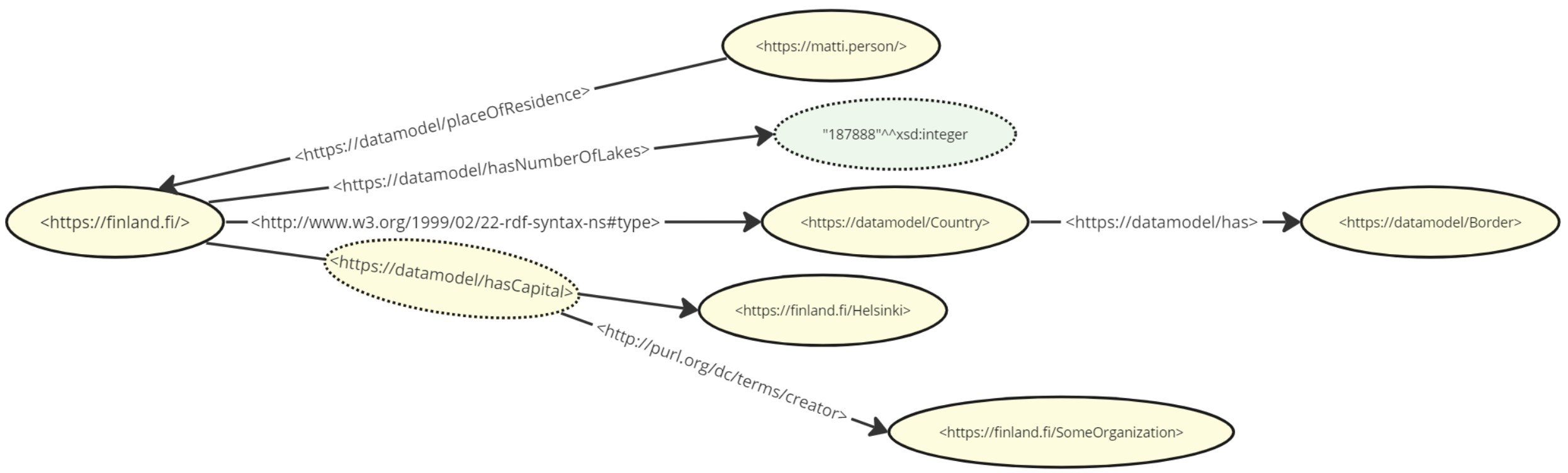
Above, you can see another triple where the creator of the <https://datamodel/hasCapital> resource is stated as being some organization under the <https://finland.fi/> namespace.
Data and Model Can Coexist
From the diagrams above it is evident that both individuals ("instances") and classes are named the same way and can coexist in the same graph. From the plain linked data perspective such a distinction doesn't even exist: there are just resources pointing to other resources with RDF. Where the distinction becomes important is when the data is interpreted through the lens of a knowledge description language where some of the resources have a special meaning for the processing software. The meaning of these resources become evident when we discuss the core vocabularies and application profiles.
Relationships Are Binary
Third key takeaway is that all relationships are binary. This means that these kind of structures (n-ary relationships) are not possible:
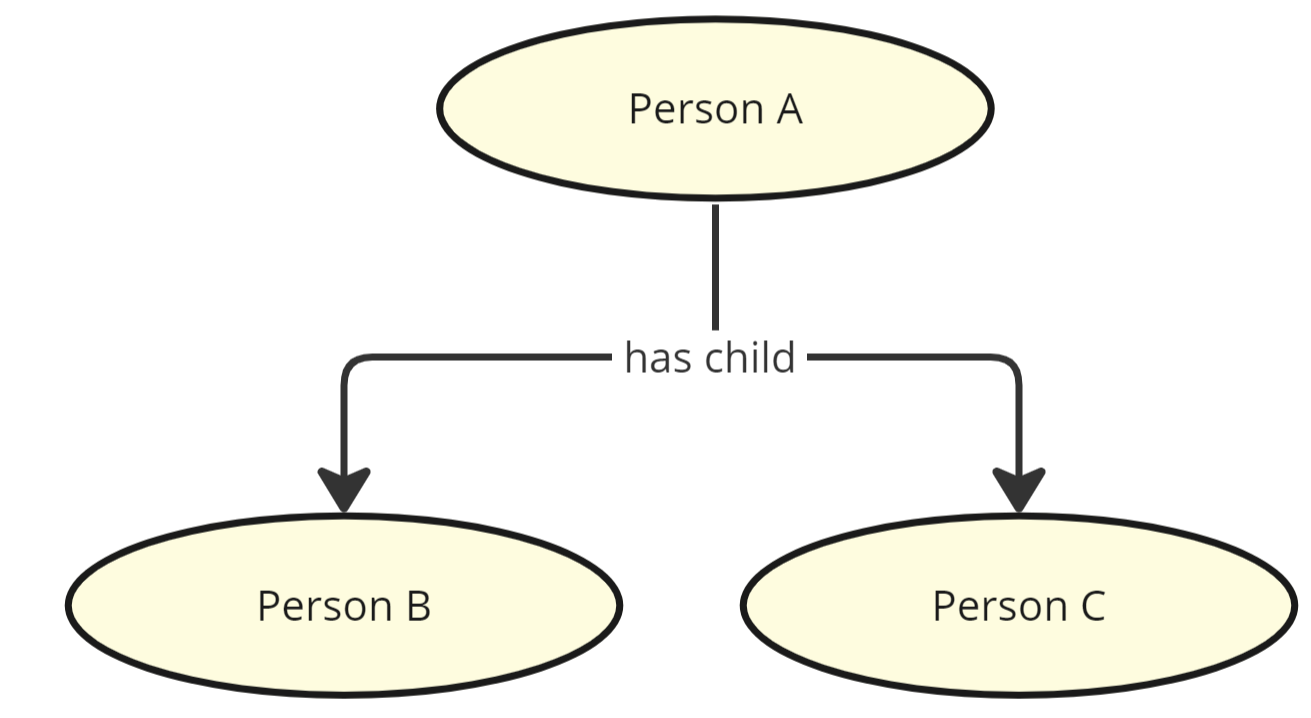
Stating this would always require two triples with each one using the same "has child" as its predicate, meaning the association is used twice. This means that treating them as one requires an additional grouping structure, for example in the case where all of the child associations would share some feature that we do not want to replicate for each individual association.
You're not Modelling records but the Entities
What all the resources in a linked data dataset are depends of course entirely on the use case at hand. In general though, there is a deep philosophical distinction between how linked data and traditional data approach modelling. Traditionally data modelling is done in a siloed way with an emphasis on modelling records, in other words a data structure that describes a set of data for a specific use case. As an example, different information systems might hold data about an individual's income taxes, medical history etc. These data sets relate to the individual indirectly via some kind of a permanent identifier, such as the finnish Personal Identity Code. The identifier nor the records are meant to represent the concepts themselves but just a the relevant data of them. The data is typically somewhat denormalized and serves a process or system view of the domain at hand.
On the other hand, in linked data the modelling of specific entities is often approached by assuming that the minted URIs (or IRIs) are actually names for the entities themselves.
Core Vocabularies (Ontologies)
Core Vocabularies provide a structured framework to represent knowledge as a set of concepts within a domain and the relationships between those concepts. They are used extensively to formalize a domain's knowledge in a way that can be processed by computers. Ontologies allow for sophisticated inferences and queries because they can model complex relationships between entities and can include rules for how entities are connected.
RDFS (RDF Schema) is a basic ontology language providing basic elements for the description of ontologies. It introduces concepts such as classes and properties, enabling rudimentary hierarchical classifications and relationships.
OWL (Web Ontology Language) offers more advanced features than RDFS and is capable of representing rich and complex knowledge about things, groups of things, and relations between things. OWL is highly expressive and designed for applications that need to process the content of information instead of just presenting information.
Schemas
Schemas, on the other hand, are used for data validation. They define the shape of the data, ensuring it adheres to certain rules before it is processed or integrated into systems. Schemas help maintain consistency and reliability in data across different systems.
- SHACL (Shapes Constraint Language) is used to validate RDF graphs against a set of conditions. These conditions are defined as shapes and can be used to express constraints, such as the types of nodes, the range of values, or even the cardinality (e.g., a person must have exactly one birthdate).
While ontologies and schemas are the main categories, there are other tools and languages within the linked data ecosystem that also play vital roles, though they may not constitute a separate major category by themselves. These include:
SPARQL (SPARQL Protocol and RDF Query Language), which is used to query RDF data. It allows users to extract and manipulate data stored in RDF format across various sources. SPARQL can be embedded in SHACL constraints to further increase its expressivity.
SKOS (Simple Knowledge Organization System), which is used for representing knowledge organization systems such as thesauri and classification schemes within RDF.
Each tool or language serves specific purposes but ultimately contributes to the broader goals of linked data: enhancing interoperability, enabling sophisticated semantic querying, and ensuring data consistency across different systems. Ontologies and schemas remain the foundational categories for organizing and validating this data.
When transitioning from traditional modeling techniques like UML (Unified Modeling Language) or Entity-Relationship Diagrams (ERD) to linked data based modeling with tools like OWL, RDFS, and SHACL, practitioners encounter both conceptual and practical shifts. This chapter aims to elucidate these differences, providing a clear pathway for those accustomed to conventional data modeling paradigms to adapt to linked data methodologies effectively.
Conceptual Shifts
Graph-based vs. Class-based Structures
- Traditional Models: Traditional data modeling, such as UML and ERD, uses a class-based approach where data is structured according to classes which define the attributes and relationships of their instances. These models create a somewhat rigid hierarchy where entities must fit into predefined classes, and interactions are limited to those defined within and between these classes.
- Linked Data Models: Contrastingly, linked data models, utilizing primarily RDF-based technologies, adopt a graph-based approach. In these models, data is represented as a network of nodes (entities) and edges (relationships) that connect them. Each element, whether data or a conceptual entity, can be directly linked to any other, allowing for dynamic and flexible relationships without the confines of a strict class hierarchy. This structure facilitates more complex interconnections and seamless integration of diverse data sources, making it ideal for expansive and evolving data ecosystems.
From Static to Dynamic Schema Definitions
- Traditional Models: UML and ERD typically define rigid schemas intended to structure database systems where the schema must be defined before data entry and is difficult to change.
- Linked Data Models: OWL, RDFS etc. allow for more flexible, dynamic schema definitions that can evolve over time without disrupting existing data. They support inferencing, meaning new relationships and data types can be derived logically from existing definitions.
From Closed to Open World Assumption
- Traditional Models: Operate under the closed world assumption where what is not explicitly stated is considered false. For example, if an ERD does not specify a relationship, it does not exist.
- Linked Data Models: Typically adhere to the open world assumption, common in semantic web technologies, where the absence of information does not imply its negation, i.e. we cannot deduce falsity based on missing data. This approach is conducive to integrating data from multiple, evolving sources.
Entity Identification
- Traditional Models: Entities are identified within the confines of a single system or database, often using internal identifiers (e.g., a primary key in a database). Not all entities (such as attributes of a class) are identifiable without their context (i.e. one can't define an attribute with an identity and use it in two classes).
- Linked Data Models: Linked data models treat all elements as atomic resources that can be uniquely identified and accessed. Each resource, whether it's a piece of data or a conceptual entity, is assigned a Uniform Resource Identifier (URI). This ensures that every element in the dataset can be individually addressed and referenced, enhancing the accessibility and linkage of data across different sources.
Practical Shifts
Modeling Languages and Tools
- Traditional Models: Use diagrammatic tools to visually represent entities, relationships, and hierarchies, often tailored for relational databases.
- Linked Data Models: Employ declarative languages that describe data models in terms of classes, properties, and relationships that are more aligned with graph databases. These tools often focus on semantics and relationships rather than just data containment.
Data Integrity and Validation
- Traditional Models: Data integrity is managed through constraints like foreign keys, unique constraints, and checks within the database system.
- Linked Data Models: SHACL is used for validating RDF data against a set of conditions (data shapes), which can include cardinality, datatype constraints, and more complex logical conditions.
Interoperability and Integration
- Traditional Models: Often siloed, requiring significant effort (e.g. ETL solutions, middleware) to ensure interoperability between disparate systems.
- Linked Data Models: Designed for interoperability, using RDF (Resource Description Framework) as a standard model for data interchange on the Web, facilitating easier data merging and linking.
Transition Strategies
Understanding Semantic Relationships
- Invest time in understanding how OWL and RDFS manage ontologies, focusing on how entities and relationships are semantically connected rather than just structurally mapped.
Learning New Validation Techniques
- Learn SHACL to understand how data validation can be applied in linked data environments, which is different from constraint definition in relational databases.
Adopting a Global Identifier Mindset
- Embrace the concept of using URIs for identifying entities globally, which involves understanding how to manage and resolve these identifiers over the web.
- It is also worth learning about how URIs differ from URNs and URLs, how they enable interoperability with other identifier schemas (such as using UUIDs), what resolving identifiers means, and how URIs and their namespacing can be used to use URIs in a local scope.
Linked Data Modeling in practice
You might already have a clear-cut goal for modeling, or alternatively be tasked with a still loosely defined goal of improving the management of knowledge in your organization. As a data architect, you're accustomed to dealing with REST APIs, PostgreSQL databases, and UML diagrams. But the adoption of technologies like RDF, RDFS, OWL, and SHACL can elevate your data architecture strategies. Here is a short list explaining some of the most common use-cases as they would be implemented here:
Conceptual and logical models and database schemas
For conceptual and logical models, you should create a Core Vocabulary (i.e. an OWL ontology). You can do both lightweight conceptual modeling by merely specifying classes and their interrelationships with associations, or a more complex and comprehensive model by including attributes, their hierarchies and attribute/relationship-based constraints. In either case, the same OWL ontology acts both as a formally defined conceptual and logical model, there is no need for an atrificial separation of the two. This also helps to avoid inconsistencies cropping up between the two. The primary advantage of basing these models on OWL is the ability to use inferencing engines to logically validate the internal consistency of the created models, which is not possible with traditional conceptual and logical models.
For relational-RDF mappings, please check the following resources:
- The W3C R2RML recommendation: https://www.w3.org/TR/r2rml/
- LinkML mapping language: https://linkml.io/linkml/
Regarding database schemas, even for relational databases, conceptual and logical models are necessary to define the structure and interrelationships of data. In the case
RDFS and OWL can also be used to document the schema of an existing relational database in RDF format. This can serve as an interoperability layer to help integrate the relational database with other systems, facilitating easier data sharing and querying across different platforms.
You should create
- Defining API specifications:
- Defining message schemas:
Which one to create: a Core Vocabulary or Application profile?
Which model type should you start with? This naturally depends on your use-case. You might be defining a database schema, building a service that distributes information products adhering to a specific schema, trying to integrate two datasets... In general, all these and other use-cases start with the following workflow:
- In general the expectation is that your data needs to be typed, structured and annotated by metadata at least on some level. This is where you would traditionally employ a conceptual model and terminological or controlled vocabularies as the semantic basis for your modeling. You might have already done this part, but if not, the FI-Platform can assist you with ending up with a logically consistent conceptual model.
- Your domain's conceptual model needs to be created in a formal semantic form as a core vocabulary. The advantage compared to a traditional separate conceptual and logical model is that here they are part of the same definition and the logical soundness of the definitions can be validated. Thus, there is no risk of ending up with a logical model that would be based on a conceptually ambiguous (and potentially internally inconsistent) definition.
- When you've defined and validated your core vocabulary, you have a sound basis to annotate your data with. Annotating in principle consists both of typing and describing the data (i.e. adding metadata). Annotating your data allows for inferencing (deducing indirect facts from the data), logical validation (checking if the data adheres to the definitions set in the core vocabulary), harmonizing datasets, etc.
- Finally, if you intend to create schemas e.g. for validating data passing through an API or ensuring that a specific message payload has a valid structure and contents, you need to create an application profile. Application profiles are created based on core vocabularies, i.e. an application profile looks for data annotated with some core vocabulary concepts and then applies validation rules.
Thus, the principal difference between these two is:
- If you want to annotate data, check its logical soundness or infer new facts from it, you need a core vocabulary. With a core vocabulary you are essentially making a specification stating "individuals that fit these criteria belong to these classes".
- If you want to validate the data structure or do anything you'd traditionally do with a schema, you need an application profile. With an application profile you are essentially making a specification stating "graph structures matching these patterns are valid".
Core Vocabularies in a Nutshell
As mentioned, the idea of a Core Vocabulary is to describe semantically the resources (entities) you will be using to describe your data with. In other words, what typically ends up as a conceptual model documentation or diagram, is now described by a formal model.
Core vocabularies are technically speaking ontologies based on the Web Ontology Language (OWL) which is a knowledge description language. OWL makes it possible to connect different data models (and thus data annotated with different models) and make logical inferences on which resources are equivalent, which have a subset relationship, which are complements etc. As the name implies, there is a heavy emphasis on knowledge - we are not simply labeling data but describing what it means in a machine-interpretable manner.
A key feature in OWL is the capability to infer facts from the data that are not immediately apparent - especially in large and complex datasets. This makes the distinction between core and derived data more apparent than in traditional data modeling scenarios, and helps to avoid modeling practices that would increase redundancy or potential for inconsistencies in the data. Additionally, connecting two core vocabularies allows for inferencing between them (and their data) and thus harmonizing them. This allows for example revealing parts in the datasets that represent the same data despite having being named or structured differently.
The OWL language has multiple profiles for different kind of inferencing. The one currently selected for the FI-Platform (OWL 2 EL) is computationally simple, but still logically expressive enough to fulfill most modeling needs. An important reminder when doing core vocabulary modeling is to constantly ask: is the feature I am after part of a specific use case (and thus application profile) or is it essential to the definition of these concepts?
Application Profiles in a Nutshell
Application profiles fill the need to not only validate the meaning and semantic consistency of data and specifications, but to enforce a specific syntactic structure and contents for data.
Application profiles are based on the Shapes Constraint Language (SHACL), which does not deal with inferencing and should principally be considered a pattern matching validation language. A SHACL model can be used to find resources based on their type, name, relationships or other properties and check for various conditions. The SHACL model can also define the kind of validation messages that are produced for the checked patterns.
Following the key Semantic Web principles, SHACL validation is not based on whitelisting (deny all, permit some) like traditional closed schema definitions. Instead, SHACL works by validating the patterns we are interested in and ignoring everything else. Due to the nature of RDF data, this doesn't cause problems, as we can simply dump all triples from the dataset that are not part of the validated patterns. Also, it is possible to extend SHACL validation by SHACL-SPARQL or SHACL Javascript extensions to perform a vast amount of pre/postprocessing and validation of the data, though this is not currently supported by the FI-Platform nor within the scope of this document.
X.3 Core Vocabulary modeling
When modeling a core vocabulary, you are essentially creating three types of resources:
Attributes
Attributes are in principle very similar to attribute declarations in other data modeling languages. There are some differences nevertheless that you need to take into account:
- Attributes can be used without classes. For an attribute definition, one can specify
rdfs:domainand/orrdfs:range. The domain refers to the subject in the<subject, attribute, literal value>triple, and range refers to the literal value. Basically what this means is that when such a triple is found in the data, its subject is assumed to be of the type specified byrdfs:domain, and the datatype is assumed to be of the type specified byrdfs:range. - The attribute can be declared as functional, meaning that when used it will only have at most one value. As an example, one could define a functioanl attribute called
agewith a domain ofPerson. This would then indicate that each instance ofPersoncan have at most one literal value for theirageattribute. On the other hand, if the functional declaration is not used, the same attribute (e.g.nickname) can be used to point to multiple literal values. - Attribute datatypes are by default XSD datatypes, which come with their own datatype hierarchy (see here).
- In core vocabularies it is sometimes preferable to define attribute datatype on a very general level, for example as
rdfs:Literal. This allows using the same attribute in a multitude of application profiles with the same intended semantic meaning but enforcing a context-specific precise datatype in each application profile. - Attributes can have hierarchies. This is an often overlooked but useful feature for inferencing. As an example, you could create a generic attribute called
Identifierthat represents the group of all attributes that act as identifiers. You could then create sub-attributes, for exampleTIN(Tax Identification Number),HeTu(the Finnish personal identity code) and so on. - Attributes can have explicit equivalence declarations (i.e. an attribute in this model is declared to be equivalent to some other attribute).
Associations
Associations are similarly not drastically different compared to other languages. There are some noteworthy things to consider nevertheless:
- Associations can be used without classes as well. The
rdfs:domainandrdfs:rangeoptions can here be used to define the source and target classes for the uses of a specific association. As an example, the associationhasParentmight havePersonas both its domain and range, meaning that all triples using this association are assumed to describe connections between instances ofPerson. - Associations in RDF are binary, meaning that the triple
<..., association, ...>will always connect two resources with the association acting as the predicate. - Associations can have hierarchies similarly to attributes.
- Associations have flags for determining whether they are reflexive meaning that both the subject and object of the association are assumed to be the same resource, whether they are transitive (meaning that if classes A and B as well as B and C are connected by association X, then this is equivalent to declaring that class A is connected to C by association X).
- Associations can have explicit equivalence declarations (i.e. an association in this model is declared to be equivalent to some other association).
Classes
Classes form the most expressive backbone of OWL. Classes can simply utilize the rdfs:subClassOf association to create hierarchies, but typically classes contain property restrictions - in the current FI-Platform case really simple ones. A class can simply state existential restrictions requiring that the members of a class must contain specific attributes and/or associations. Further cardinality restrictions are not declared here, as the chosen OWL profile does not support them, and cardinality can be explicitly defined in an application profile. In order to require specific associations or attributes to be present in an instance of a class, they must exist, as associations and attributes are never owned by a class, unlike in e.g. UML. They are individual definitions that are simply referred to by the class definition. This allows for situations where an extremely common definition (for example a date of birth or surname) can be defined only once in one model and then reused endlessly in all other models without having to be ever redefined.
Classes are not templates in the vein of programming or UML style classes but mathematical sets. You should think of a class definition as being the definition of a group: "instances with these features belong to this class". Following the Semantic Web principles, it is possible to declare a resource as an instance of a class even if it doesn't contain all the attribute and association declarations required by the class "membership". On the other hand, such a resource would never be automatically categorized as being a member of said class as it lacks the features required for the inference to make this classification.
Similarly to associations and attributes, classes have equivalence declarations. Additionally, classes can be declared as non-intersecting. It is important to understand that classes being sets doesn't by default in any way force them to be strictly separated. From the perspective of the inference reasoner, classes for inanimate objects and people could well be overlapping, unless it is explicitly declared logically inconsistent. With a well laid out class hierarchy, simply declaring a couple of superclasses as non-intersecting will automatically make all their subclasses non-intersecting as well.
X.4. Application profile modeling
With application profiles we use strictly separate set of terms to avoid mixing up the core vocabulary structures we are validating and the validating structures themselves. The application profile entities are called restrictions:
Attribute and association restrictions
These restrictions are tied to specific attribute and association types that are used in the data being validated. Creating a restriction for a specific core vocabulary association allows it to be reused in one or more class restrictions. In the future the functionality of the FI-Platform might be extended to cover using attribute and association restrictions individually without class restrictions, but currently this is not possible.
Common restrictions for both attributes and associations are the maximal and minimal cardinalities: there is no inherent link between the cardinalities specified in SHACL and the functional switch defined in the core vocabulary attribute as they have different use-cases. It is nevertheless usually preferable keep these two consistent (a functional core attribute should not be allowed or required to have a cardinality of > 1 in an application profile). Allowed, required and default values are also common features for both restriction types.
The available features for attribute restrictions specifically are partially dependent on the datatype of the attribute. As mentioned before, it is preferable to set the exact required datatype here and have a wider datatype in the core vocabulary attribute. For string types, max and min lengths, regex validation pattern, and languages. For numerical types, min and max values are currently supported.
For association restrictions, the currently supported extra restriction is the class type requirement for the association restriction target (i.e. what type of an instance must be at the object end of the association).
Class restrictions
Similarly to core vocabulary classes, also class restrictions utilize a group of predefined attribute and association definitions. Again, this allows for example the specification of some extremely reusable association and attribute restrictions which can then be reused a multitude of times in various application profiles.
The target class definition works by default on the level of RDFS inferencing (in other words, it will validate the instances of the specified class and all its subclasses).
Class restrictions don't operate in a set-theoretical manner like core vocabulary definitions, but there is a way to implement "inheritance" in validated classes. If a class restriction utilizes another class restriction, its target classes contents are checked against both of these class restrictions.
General word of caution on modeling
SHACL is a very flexible language and due to this nature it allows the creation of validation patterns that might seem legit but are actually unsatisfiable by any instance data. As an example, the utilization of other class restrictions might lead to a situation where an attribute can never be validated as it is required to conform to two conflicting datatypes at the same time.
Also, whereas the OWL specification is monolithic and cannot be extended or modified, SHACL can be extended with a multitude of ways, for example by embedding SPARQL queries or Javascript processing in SHACL constraints. The standard allows for this, but naturally it is dependent on the used SHACL validator, which extensions are supported. The FI-Platform in its current form adheres to the core specification (vanilla) SHACL.
A final note regarding SHACL validation is that its results are also dependent on whether inferencing is executed on the data prior to validation or not. The SHACL validator by default does not know or care about OWL inferencing, and works strictly based on the triples it sees declared in the data. It is recommended that inferencing is run before validation to ensure there are no implicit facts that the SHACL validator could miss. Also, it is important to remember that the core vocabulary declarations for the instance data must be included in the data graph to be validated. The SHACL validator will not resolve anything outside the data graph, and will match patterns only based on what it sees in the data graph.