This page describes the principles of creating core vocabularies and application profiles. It is important to understand these principles so that any ambiguities are avoided.
Unlike with many UML class diagrams, there is no possibility that the contents of a core vocabulary or application profile could be interpreted in a multitude of ways, as they are both based on formal knowledge representation languages and thus can be unambiguously validated.
For this reason, it is important that the vocabularies and profiles you create are semantically equivalent to what you intend them to be. It is not enough to describe with human-readable annotations what your classes, attributes, associations and constraints mean, but necessary to specify this human-readable intent with logic. This document helps you to achieve this goal.
1.1. The Linked Data Modeling paradigm
First you need to consider the type of model you are creating. When modeling on the FI-Platform, you should not think in the traditional terms of conceptual, logical and physical models, nor in the terms of typical UML profiles. Models created on the FI-Platform can be used for these purposes, but the RDF-based knowledge representation language used here has more expressivity than typical data description languages.
When modeling on the FI-Platform, you should keep in mind these essential principles:
You're working with a graph
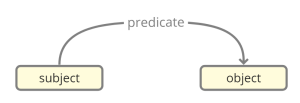
The RDF data model is a very generalized graph which is able to describe many kinds of data structures. Both data models and instance data are described with the same structure: triples of two nodes and an edge connecting them. RDF graphs can be represented in a very simple three column tabular form: <subject, predicate, object>. Each subject and object are some entities, or resources in the linked data jargon (for example classes or instances of classes, literal values etc.) and predicates are entities that link them together. For example a subclass association between classes A and B would be represented as <B, subclass, A>, or visually as two nodes in a graph linked by a subclass edge. Attribute values are represented with the same structure, with the attribute entity acting as the edge and the literal attribute value acting as the object node: <A, someAttribute, "foobar">.
Polyhierarchies are supported
In traditional data modeling multiple inheritance (typically the only way to represent hierarchical structures) is typically not allowed or at least severely limited. Instead, building hierarchies with multiple superclasses is allowed and in some cases even necessary.
All entities have identities
Usually some entities in data modeling languages don't have an identity as they are inherently part of their defining entities. As an example, UML attributes are not entities that can be individually referenced, they exist only as part of the class that defined them. This means that a model might have multiple attributes with the same identifying name and meaning but there is no technical way to straightforwardly identify these attributes as being "the same".
In RDF, every resource (entity) has an unique identifier, thus allowing RDF the reuse of any defined resource which reduces data duplication and overlapping definitions. Both data structures and instance data share the same URI-based naming principle, which on the FI-Platform is HTTPS IRI.
Resource identifiers can generally be minted (declared) as anything that adheres to the URI RFC 3986, but on the FI-Platform minting is controlled by enforcing a namespace which is under https://iri.suomi.fi/. This ensures that model resources will not accidentally collide with resources elsewhere on the web.
No strict separation between data and metadata
Due to the abovementioned identifiers, it is possible to add descriptive metadata to any entity either by stating the metadata by the entity itself, or externally by referring to the entity by its identifier.
No strict separation between classes and instances
So-called punning means that classes can act also as instances, there is no hard line separating them (though this doesn't mean the situation would be ambiguous, there are clear logical rules for deducing the state of affairs).
No strict separation between conceptual and logical model
When properly annotated, the actual model itself acts as a machine-readable conceptual model with a rich layer of logical model features on top of it. This also applies to schemas (application profiles), where the schema itself can be directly annotated. The conceptual link can be achieved for example by describing the entities conceptually as a SKOS vocabulary (also RDF-based) and referring to the SKOS concepts from the data model (thus creating a machine-readable link between the terminological and logical models).
1.2. Which one to create: a Core Vocabulary or Application profile?
Which model type should you start with? This naturally depends on your use-case. You might be defining a database schema, building a service that distributes information products adhering to a specific schema, trying to integrate two datasets... In general, all these and other use-cases start with the following workflow:
- In general the expectation is that your data needs to be typed, structured and annotated by metadata at least on some level. This is where you would traditionally employ a conceptual model and terminological or controlled vocabularies as the semantic basis for your modeling. You might have already done this part, but if not, the FI-Platform can assist you with ending up with a logically consistent conceptual model.
- Your domain's conceptual model needs to be created in a formal semantic form as a core vocabulary. The advantage compared to a traditional separate conceptual and logical model is that here they are part of the same definition and the logical soundness of the definitions can be validated. Thus, there is no risk of ending up with a logical model that would be based on a conceptually ambiguous (and potentially internally inconsistent) definition.
- When you've defined and validated your core vocabulary, you have a sound basis to annotate your data with. Annotating in principle consists both of typing and describing the data (i.e. adding metadata). Annotating your data allows for inferencing (deducing indirect facts from the data), logical validation (checking if the data adheres to the definitions set in the core vocabulary), harmonizing datasets, etc.
- Finally, if you intend to create schemas e.g. for validating data passing through an API or ensuring that a specific message payload has a valid structure and contents, you need to create an application profile. Application profiles are created based on core vocabularies, i.e. an application profile looks for data annotated with some core vocabulary concepts and then applies validation rules.
Thus, the principal difference between these two is:
- If you want to annotate data, check its logical soundness or infer new facts from it, you need a core vocabulary. With a core vocabulary you are essentially making a specification stating "individuals that fit these criteria belong to these classes".
- If you want to validate the data structure or do anything you'd traditionally do with a schema, you need an application profile. With an application profile you are essentially making a specification stating "graph structures matching these patterns are valid".
Core Vocabularies in a Nutshell
As mentioned, the idea of a Core Vocabulary is to describe semantically the resources (entities) you will be using to describe your data with. In other words, what typically ends up as a conceptual model documentation or diagram, is now described by a formal model.
Core vocabularies are technically speaking ontologies based on the Web Ontology Language (OWL) which is a knowledge description language. OWL makes it possible to connect different data models (and thus data annotated with different models) and make logical inferences on which resources are equivalent, which have a subset relationship, which are complements etc. As the name implies, there is a heavy emphasis on knowledge - we are not simply labeling data but describing what it means in a machine-interpretable manner.
A key feature in OWL is the capability to infer facts from the data that are not immediately apparent - especially in large and complex datasets. This makes the distinction between core and derived data more apparent than in traditional data modeling scenarios, and helps to avoid modeling practices that would increase redundancy or potential for inconsistencies in the data. Additionally, connecting two core vocabularies allows for inferencing between them (and their data) and thus harmonizing them. This allows for example revealing parts in the datasets that represent the same data despite having being named or structured differently.
The OWL language has multiple profiles for different kind of inferencing. The one currently selected for the FI-Platform (OWL 2 EL) is computationally simple, but still logically expressive enough to fulfill most modeling needs. An important reminder when doing core vocabulary modeling is to constantly ask: is the feature I am after part of a specific use case (and thus application profile) or is it essential to the definition of these concepts?
Application Profiles in a Nutshell
Application profiles fill the need to not only validate the meaning and semantic consistency of data and specifications, but to enforce a specific syntactic structure and contents for data.
Application profiles are based on the Shapes Constraint Language (SHACL), which does not deal with inferencing and should principally be considered a pattern matching validation language. A SHACL model can be used to find resources based on their type, name, relationships or other properties and check for various conditions. The SHACL model can also define the kind of validation messages that are produced for the checked patterns.
Following the key Semantic Web principles, SHACL validation is not based on whitelisting (deny all, permit some) like traditional closed schema definitions. Instead, SHACL works by validating the patterns we are interested in and ignoring everything else. Due to the nature of RDF data, this doesn't cause problems, as we can simply dump all triples from the dataset that are not part of the validated patterns. Also, it is possible to extend SHACL validation by SHACL-SPARQL or SHACL Javascript extensions to perform a vast amount of pre/postprocessing and validation of the data, though this is not currently supported by the FI-Platform nor within the scope of this document.
1.3 Core Vocabulary modeling
When modeling a core vocabulary, you are essentially creating three types of resources:
Attributes
Attributes are in principle very similar to attribute declarations in other data modeling languages. There are some differences nevertheless that you need to take into account:
- Attributes can be used without classes. For an attribute definition, one can specify
rdfs:domainand/orrdfs:range. The domain refers to the subject in the<subject, attribute, literal value>triple, and range refers to the literal value. Basically what this means is that when such a triple is found in the data, its subject is assumed to be of the type specified byrdfs:domain, and the datatype is assumed to be of the type specified byrdfs:range. - The attribute can be declared as functional, meaning that when used it will only have at most one value. As an example, one could define a functioanl attribute called
agewith a domain ofPerson. This would then indicate that each instance ofPersoncan have at most one literal value for theirageattribute. On the other hand, if the functional declaration is not used, the same attribute (e.g.nickname) can be used to point to multiple literal values. - Attribute datatypes are by default XSD datatypes, which come with their own datatype hierarchy (see here).
- In core vocabularies it is sometimes preferable to define attribute datatype on a very general level, for example as
rdfs:Literal. This allows using the same attribute in a multitude of application profiles with the same intended semantic meaning but enforcing a context-specific precise datatype in each application profile. - Attributes can have hierarchies. This is an often overlooked but useful feature for inferencing. As an example, you could create a generic attribute called
Identifierthat represents the group of all attributes that act as identifiers. You could then create sub-attributes, for exampleTIN(Tax Identification Number),HeTu(the Finnish personal identity code) and so on. - Attributes can have explicit equivalence declarations (i.e. an attribute in this model is declared to be equivalent to some other attribute).
Associations
Associations are similarly not drastically different compared to other languages. There are some noteworthy things to consider nevertheless:
- Associations can be used without classes as well. The
rdfs:domainandrdfs:rangeoptions can here be used to define the source and target classes for the uses of a specific association. As an example, the associationhasParentmight havePersonas both its domain and range, meaning that all triples using this association are assumed to describe connections between instances ofPerson. - Associations in RDF are binary, meaning that the triple
<..., association, ...>will always connect two resources with the association acting as the predicate. - Associations can have hierarchies similarly to attributes.
- Associations have flags for determining whether they are reflexive meaning that both the subject and object of the association are assumed to be the same resource, whether they are transitive (meaning that if classes A and B as well as B and C are connected by association X, then this is equivalent to declaring that class A is connected to C by association X).
- Associations can have explicit equivalence declarations (i.e. an association in this model is declared to be equivalent to some other association).
Classes
Classes form the most expressive backbone of OWL. Classes can simply utilize the rdfs:subClassOf association to create hierarchies, but typically classes contain property restrictions - in the current FI-Platform case really simple ones. A class can simply state existential restrictions requiring that the members of a class must contain specific attributes and/or associations. Further cardinality restrictions are not declared here, as the chosen OWL profile does not support them, and cardinality can be explicitly defined in an application profile. In order to require specific associations or attributes to be present in an instance of a class, they must exist, as associations and attributes are never owned by a class, unlike in e.g. UML. They are individual definitions that are simply referred to by the class definition. This allows for situations where an extremely common definition (for example a date of birth or surname) can be defined only once in one model and then reused endlessly in all other models without having to be ever redefined.
Classes are not templates in the vein of programming or UML style classes but mathematical sets. You should think of a class definition as being the definition of a group: "instances with these features belong to this class". Following the Semantic Web principles, it is possible to declare a resource as an instance of a class even if it doesn't contain all the attribute and association declarations required by the class "membership". On the other hand, such a resource would never be automatically categorized as being a member of said class as it lacks the features required for the inference to make this classification.
Similarly to associations and attributes, classes have equivalence declarations. Additionally, classes can be declared as non-intersecting. It is important to understand that classes being sets doesn't by default in any way force them to be strictly separated. From the perspective of the inference reasoner, classes for inanimate objects and people could well be overlapping, unless it is explicitly declared logically inconsistent. With a well laid out class hierarchy, simply declaring a couple of superclasses as non-intersecting will automatically make all their subclasses non-intersecting as well.
1.4. Application profile modeling
With application profiles we use strictly separate set of terms to avoid mixing up the core vocabulary structures we are validating and the validating structures themselves. The application profile entities are called restrictions:
Attribute and association restrictions
These restrictions are tied to specific attribute and association types that are used in the data being validated. Creating a restriction for a specific core vocabulary association allows it to be reused in one or more class restrictions. In the future the functionality of the FI-Platform might be extended to cover using attribute and association restrictions individually without class restrictions, but currently this is not possible.
Common restrictions for both attributes and associations are the maximal and minimal cardinalities: there is no inherent link between the cardinalities specified in SHACL and the functional switch defined in the core vocabulary attribute as they have different use-cases. It is nevertheless usually preferable keep these two consistent (a functional core attribute should not be allowed or required to have a cardinality of > 1 in an application profile). Allowed, required and default values are also common features for both restriction types.
The available features for attribute restrictions specifically are partially dependent on the datatype of the attribute. As mentioned before, it is preferable to set the exact required datatype here and have a wider datatype in the core vocabulary attribute. For string types, max and min lengths, regex validation pattern, and languages. For numerical types, min and max values are currently supported.
For association restrictions, the currently supported extra restriction is the class type requirement for the association restriction target (i.e. what type of an instance must be at the object end of the association).
Class restrictions
Similarly to core vocabulary classes, also class restrictions utilize a group of predefined attribute and association definitions. Again, this allows for example the specification of some extremely reusable association and attribute restrictions which can then be reused a multitude of times in various application profiles.
The target class definition works by default on the level of RDFS inferencing (in other words, it will validate the instances of the specified class and all its subclasses).
Class restrictions don't operate in a set-theoretical manner like core vocabulary definitions, but there is a way to implement "inheritance" in validated classes. If a class restriction utilizes another class restriction, its target classes contents are checked against both of these class restrictions.
General word of caution on modeling
SHACL is a very flexible language and due to this nature it allows the creation of validation patterns that might seem legit but are actually unsatisfiable by any instance data. As an example, the utilization of other class restrictions might lead to a situation where an attribute can never be validated as it is required to conform to two conflicting datatypes at the same time.
Also, whereas the OWL specification is monolithic and cannot be extended or modified, SHACL can be extended with a multitude of ways, for example by embedding SPARQL queries or Javascript processing in SHACL constraints. The standard allows for this, but naturally it is dependent on the used SHACL validator, which extensions are supported. The FI-Platform in its current form adheres to the core specification (vanilla) SHACL.
A final note regarding SHACL validation is that its results are also dependent on whether inferencing is executed on the data prior to validation or not. The SHACL validator by default does not know or care about OWL inferencing, and works strictly based on the triples it sees declared in the data. It is recommended that inferencing is run before validation to ensure there are no implicit facts that the SHACL validator could miss. Also, it is important to remember that the core vocabulary declarations for the instance data must be included in the data graph to be validated. The SHACL validator will not resolve anything outside the data graph, and will match patterns only based on what it sees in the data graph.