Esikoulutetun kielimallin käyttö
Botissa on mahdollista ottaa käyttöön esikoulutettu kielimalli. Nykyään on saatavilla useita avoimia kielimalleja, jotka on koulutettu käyttäen valtavia määriä tekstidataa. Näitä malleja käyttäen voidaan parantaa bottien luonnollisen kielen tunnistusta huomattavasti.
Ilman kielimallin käyttöä botin luonnollisen kielen tunnistus perustuu sanojen ja lauseiden merkkijonojen samankaltaisuuteen. Tällöin jos käyttäjä sanoo esim. "haluan bussilipun", botti tunnistaa tarpeen lipulle bussiin, mikäli tämä on koulutusdatassa määritelty. Botti ei kuitenkaan osaa yhdistää sanaa "linja-auto" sanaan "bussi", ellei tätäkin sanaa ole erikseen annettu botille koulutusdatassa.
Kielimallien avulla botti osaa tunnistaa myös semanttisia samankaltaisuuksia, eli merkitykseltään samankaltaisia sanoja ja ilmaisuja. Tällöin esimerkiksi jos koulutusdatassa on määritelty sana "päivällinen", botti osaa yhdistää siihen sanat "ruoka" tai "ravintola" ilman, että näitä tarvitsee erikseen määritellä koulutusdatassa. Kielimallin käyttö helpottaa siis koulutusdatan luomista, koska kuiskaajan ei tarvitse etukäteen tunnistaa kaikkia mahdollisia sanoja, joilla käyttäjät voivat hakea tiettyä palvelua.
On olemassa myös useilla kielillä koulutettuja valmiita kielimalleja, joita käyttäen botti voisi tunnistaa syötteen oikein monella eri kielellä annettuna. AuroraAI-chatbotissa ollaan toistaiseksi testattu usealla kielellä koulutettua Googlen BERT-kielimallia.
Kielimallien käytön suurin varjopuoli on suurempi resurssien (muisti ja prosessoriteho) tarve, ja sitä kautta suuremmat käyttökustannukset. Botin koulutus BERT-kielimallin kanssa vaatii yli 10GB muistia, joten botilla olisi hyvä olla 12 tai 16GB muistia käytettävissä koulutuksen aikana.
Kielimallin käyttöönotto botissa
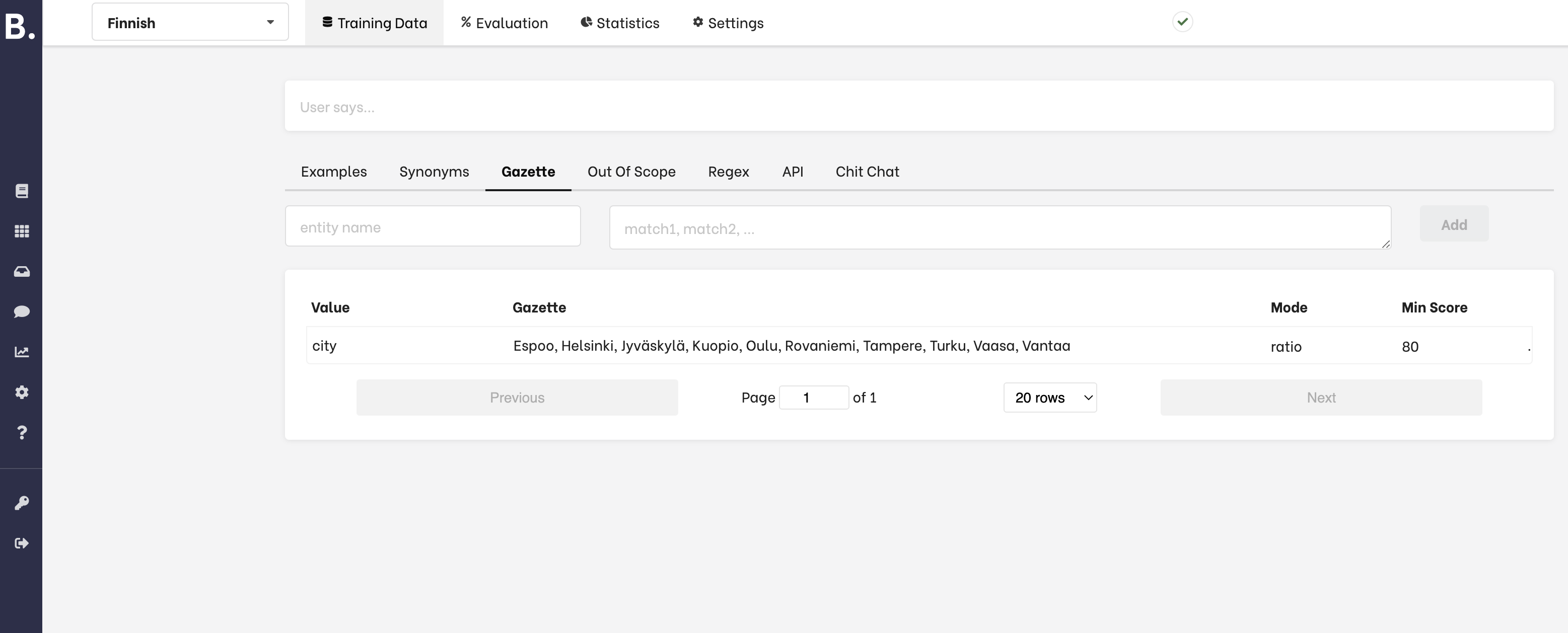
- Avaa NLU näkymästä Settings-välilehti
Varmista, että Pipeline-konfiguraatiossa on mukana seuraavat rivit, joka määrittelevät LanguageModelFeaturizer-komponentin:
Gazette
Botfrontin gazette-toiminnon tarkoitus on auttaa tunnistamaan käyttäjän antamia tietoja, jotka kerätään entiteetteinä.
Gazetelle annetaan lista vaihtoehtoja tietylle entiteetille (esim. käyttäjän kunta). Kun käyttäjä antaa syötteen tälle entiteetille, gazette vertaa tätä listan arvoihin sumeaa logiikkaa käyttäen, ja tallentaa entiteetiksi listalta arvon, joka parhaiten vastaa käyttäjän syötettä. Tällä tavalla on mahdollista tunnistaa käyttäjän antama arvo tarkasti pienistä kirjoitusvirheistä tai erilaisista kirjoitusasuista huolimatta.
Gazetelle annetaan myös kynnysluku väliltä 0-100 (100 vastaa täydellistä samankaltaisuutta), joka määrittää kuinka paljon syöte saa poiketa listan arvoista. Mikäli syöte ei vastaa mitään listan arvoa tarpeeksi tarkasti, syöte tallennetaan entiteettiin sellaisenaan.
Gazette-toiminnon käyttöönotto
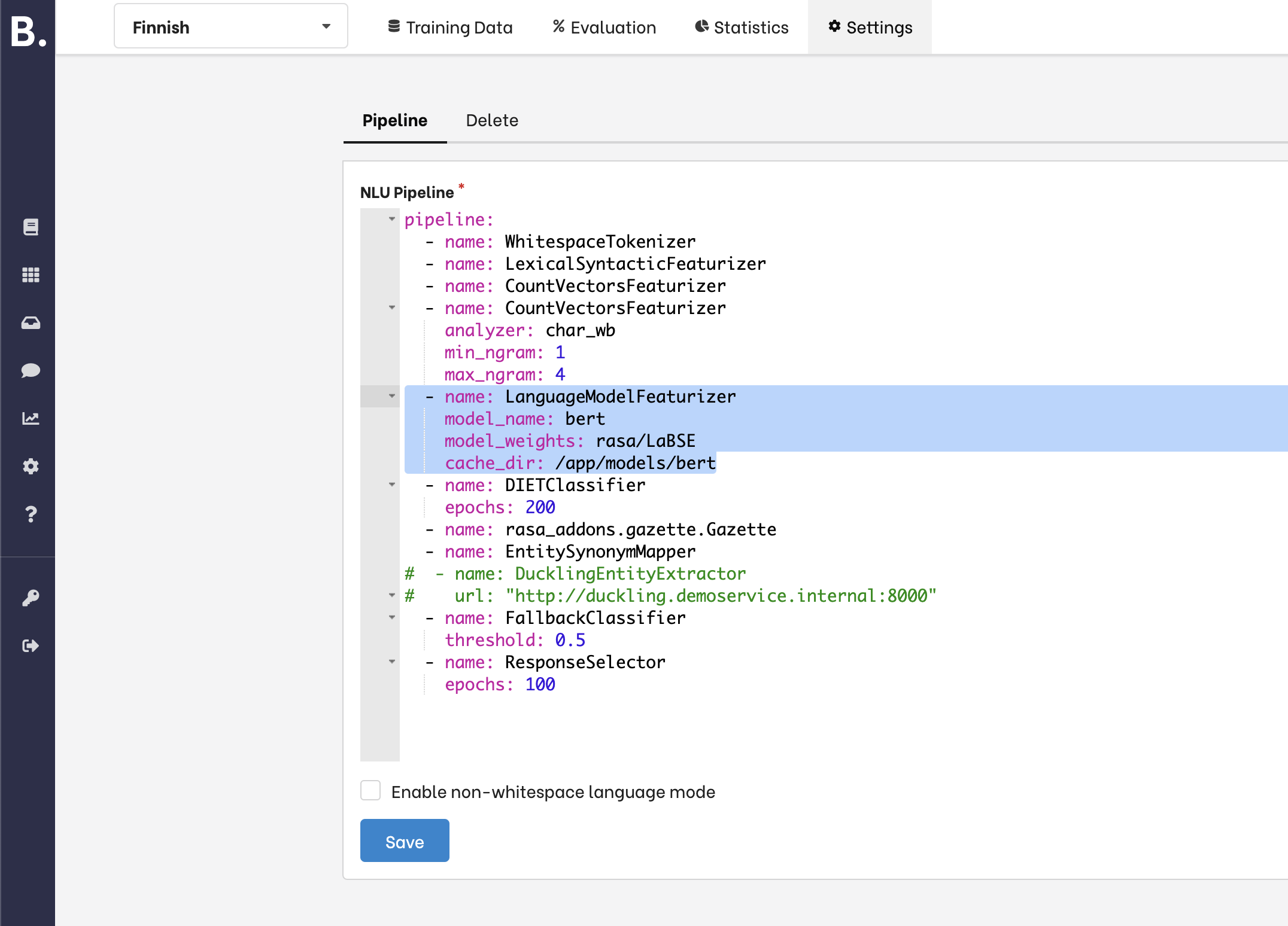
- Avaa NLU näkymästä Settings-välilehti
Varmista, että gazette on mukana Pipeline-konfiguraatiossa; tässä voi määritellä myös oletusarvon gazeten kynnysluvulle:
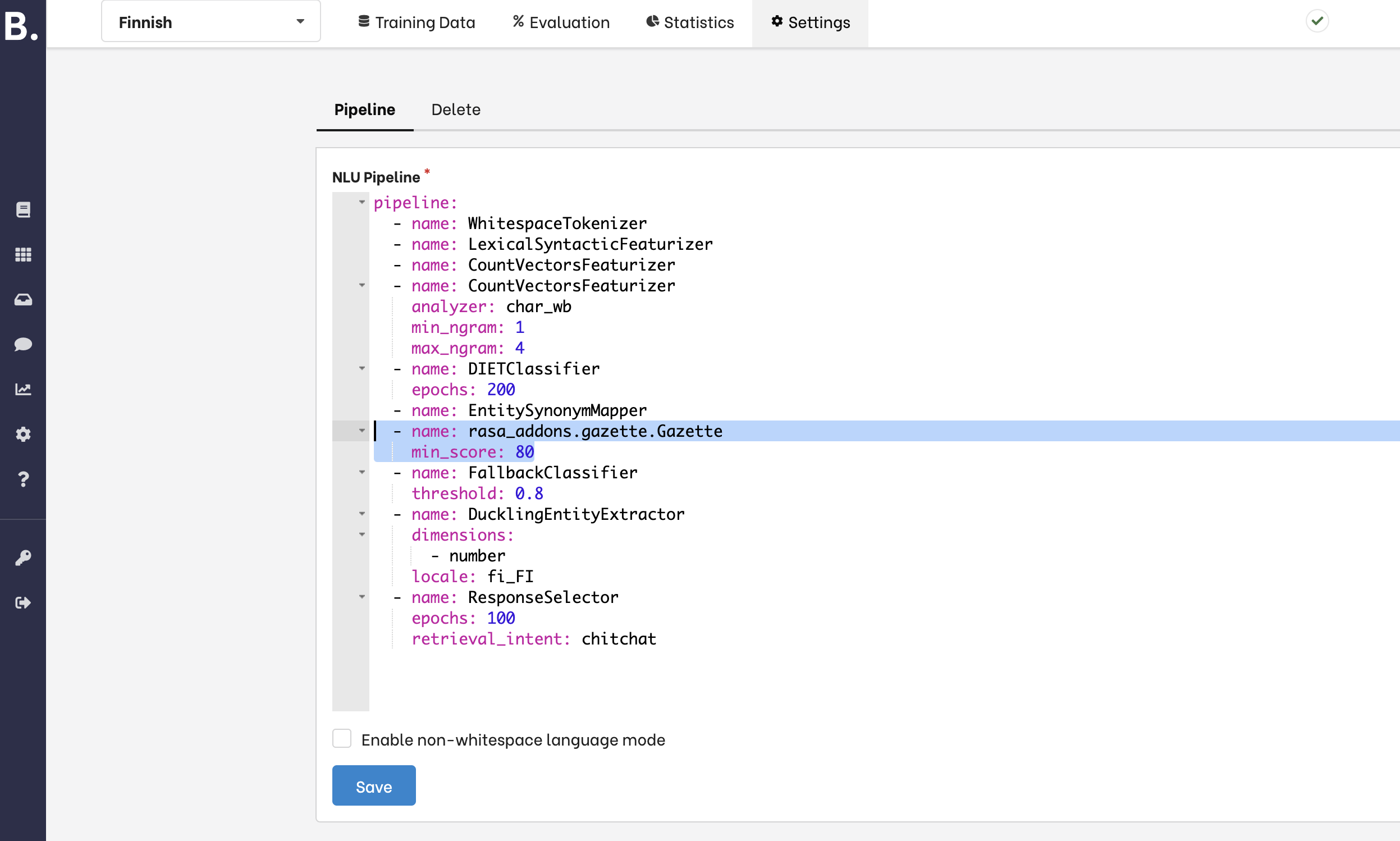
- Avaa NLU-näkymästä välilehti Training data - Gazette
- Lisää halutun entiteetin nimi "entity name" -kenttään, ja lista vaihtoehdoista viereiseen kenttään
- Mode-kenttä valitsee, mitä metodia pisteytyksessä käytetään, tätä ei tarvitse muuttaa
- Min scorella voidaan määrittää kynnysluku entiteetikohtaisesti